Effective Logging in Threaded or Multiprocessing Python Applications
In Python development, logging is not only good practice; it is vital. Logging is critical for understanding the execution flow of an application and helps in debugging potential issues. The importance of logging for developing reliable and maintainable Python applications cannot be overstated.
Python provides capabilities for running concurrent operations—either in a threaded (single process) or multiple process environment. But what implications do these different approaches have on logging? What unique challenges might they present?
In this post, we’ll explore these questions and more. We’ll look at the differences between threading and multiprocessing in Python and how to handle logging in each environment effectively. Finally, we’ll demonstrate how to aggregate our Python logs and use a centralized log management platform.
Let’s quickly review the basics of Python logging.
Basics of Python logging
Python comes with a flexible, built-in module for logging you can adapt to various use cases. Using the Python logging module, you can log runtime events in applications of any size.
To see logging in practice, let’s consider this simple Python application:
# simple-logging.py import logging |
When we run this application via the command line, the output looks like this:
$ python3 simple-logging.py |
In this example, we used logging.info() to emit log messages with level INFO. We used logging.basicConfig() to set the minimum log level to INFO, which means the logger will handle all messages with level INFO and above (WARNING, ERROR, and CRITICAL). The default basicConfig level is WARNING.
Logging in a single thread environment
The above example Python application runs in a single thread environment, the default environment for applications not explicitly calling for multiple threads or processes. In a single-threaded environment, Python’s logging module is straightforward and effective.
Creating a log entry is as simple as calling a function—such as logging.info()—with the message you want to log. These log messages are written sequentially as the program executes, creating a reliable and chronological account of your application’s behavior.
Logging in a single-threaded environment is simple. You don’t need to worry about the challenges of concurrent access to a log file. Log messages are guaranteed to be written in the order they occur, making tracking the sequence of operations and troubleshooting issues easier.
Understanding threading and multiprocessing in Python
In Python, threading and multiprocessing are two distinct approaches for achieving concurrent execution. Multiple threads can run in a single process, sharing the same memory space. This makes sharing data among them straightforward. Although individual threads are lighter than processes, only one thread can execute in a single process at a time. Therefore, threading is unable to use multiple cores for genuinely parallel execution.
In contrast, multiprocessing involves spawning multiple processes. Each process runs its own Python interpreter and has its own memory space. However, data sharing between processes is more complex because of the separate memory spaces.
What are the implications of these approaches for logging?
Since threads share the same memory space, in a threaded environment, they can write to the same log file without issue. However, in a multiprocessing environment, each process will have independent logger instances. Multiple processes writing to the same log file introduce the risk of data loss or corruption. Logging in a multiprocessing environment requires special handling and techniques, which we will cover below.
First, let’s cover the more straightforward case: logging from multiple threads within a single process.
Logging in a threaded environment
All threads operate in the same memory space in a threaded environment, similar to a single-threaded application. However, Python’s logging module is thread-safe, able to handle the potential of threads logging messages simultaneously.
Consider the following example:
# multi-thread.py import logging |
In this example, we spawn five threads. Each thread logs a message at the start and end of a simulated task, represented by a sleep interval of two seconds.
Running this code would yield a multi-thread.log file similar to the file below:
Thread 0 is starting |
Notice that the sequence of “starting” messages reflects the order in which the threads were created. However, the “finishing” messages don’t necessarily follow the same order. This is because of the unpredictable nature of thread scheduling by the OS. Python’s logging module ensures multiple threads can write to the same file and avoids losing or overwriting any log entries. The sequence and integrity of log events are preserved as well.
Let’s look now at the complexity of logging in a multiprocessing environment.
Logging in a multiprocessing environment
When we venture into a multiprocessing environment, logging can become significantly more complicated. Each process operates in its own memory space, with its own instance of the Python interpreter and its own instance of the logging module. If multiple processes try to write to the same log file concurrently, we’re likely to encounter issues such as data loss or corruption due to the lack of coordination among the processes.
The Python documentation also states:
Logging to a single file from multiple processes is not supported, because there is no standard way to serialize access to a single file across multiple processes in Python. If you need to log to a single file from multiple processes, one way of doing this is to have all the processes log to a SocketHandler, and have a separate process which implements a socket server which reads from the socket and logs to file.
For reliable multiprocessing logging to a single location, you’ll need a workaround. Python provides guidance for possible solutions:
- Send and receive logging events across a network via a SocketHandler
- Use a Queue and a QueueHandler to send all logging events to one of the processes in your multiprocessing application
When we consider this complexity alongside the limitations of logging to a file, we begin to see the advantages of aggregating logs with a centralized logging platform.
Centralized Python logging with Loggly
Loggly® is a centralized log management service for log aggregation and analysis. You can send logs from all of your applications—regardless of the programming language used—to a central location for powerful search, real-time analytics, and visualizations. For Python applications, logs across all threads and processes can be easily and securely forwarded to Loggly over HTTPS.
Centralized logging allows you to see all logs—across applications, processes, and threads—in a single place, enabling you to troubleshoot and diagnose application issues more effectively. The complications of logging from multiple processes in Python applications go away when you send log events to a central aggregator.
Let’s look at how to do this.
1. Get Loggly token
Before we can configure our logging handler, we’ll need a token from Loggly for authentication. From our Loggly account, we navigate to Source Setup ➢ Customer Tokens. We create a new token and then copy it.
2. Configure HTTPHandler
Next, we set up the logging module to use the HTTPHandler and configure the HTTPHandler with our Loggly URL and authentication credentials. Here’s what our setup code looks like:
# loggly.py import logging |
We’ve configured our logger to send log events via HTTPS to a unique Loggly URL. Note: If you’re following along by writing the code, insert your unique Loggly token copied from the previous step.
3. Emit log messages
Now our logger is set up, we write some code to perform some logging in a threaded environment as well as in a multiprocessing environment. In our open file (loggly.py), we add the following code:
def worker(number, context, sleep_seconds): |
This code iterates through a loop five times. For each iteration, we use the multiprocessing library to spawn a new Process that executes the worker function. Each iteration also uses the threading library to create a new Thread, which also executes the worker function.
4. Check for log events at Loggly
After running our Python code, we check the Log Explorer in Loggly.
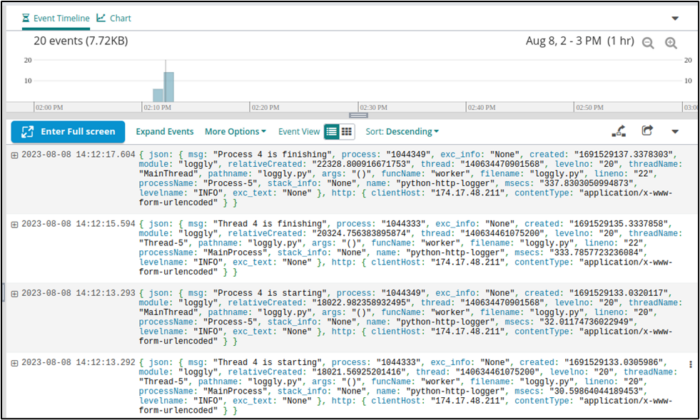
We see that we had 20 events logged. This makes sense since we iterated five times, each iteration called worker twice, and worker emits two log messages each time.
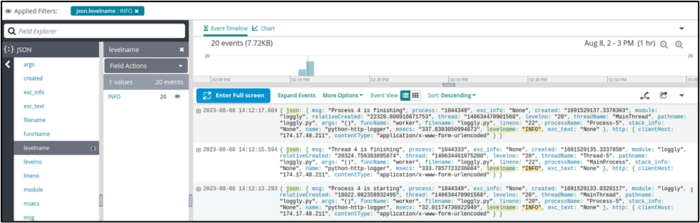
Let’s look more closely at some of our log messages.
{ json: { msg: "Thread 0 is finishing", process: "1044333", exc_info: "None", created: "1691529117.2897563", module: "loggly", relativeCreated: "2280.726909637451", thread: "140634461075200", levelno: "20", threadName: "Thread-1", pathname: "loggly.py", args: "()", funcName: "worker", filename: "loggly.py", lineno: "22", processName: "MainProcess", stack_info: "None", name: "python-http-logger", msecs: "289.75629806518555", levelname: "INFO", exc_text: "None" }, http: { clientHost: "174.17.48.211", contentType: "application/x-www-form-urlencoded" } }{ json: { msg: "Thread 0 is starting", process: "1044333", exc_info: "None", created: "1691529115.01551", module: "loggly", relativeCreated: "6.480693817138672", thread: "140634461075200", levelno: "20", threadName: "Thread-1", pathname: "loggly.py", args: "()", funcName: "worker", filename: "loggly.py", lineno: "20", processName: "MainProcess", stack_info: "None", name: "python-http-logger", msecs: "15.510082244873047", levelname: "INFO", exc_text: "None" }, http: { clientHost: "174.17.48.211", contentType: "application/x-www-form-urlencoded" } }{ json: { msg: "Process 0 is starting", process: "1044334", exc_info: "None", created: "1691529115.0159645", module: "loggly", relativeCreated: "6.93511962890625", thread: "140634470901568", levelno: "20", threadName: "MainThread", pathname: "loggly.py", args: "()", funcName: "worker", filename: "loggly.py", lineno: "20", processName: "Process-1", stack_info: "None", name: "python-http-logger", msecs: "15.964508056640625", levelname: "INFO", exc_text: "None" }, http: { clientHost: "174.17.48.211", contentType: "application/x-www-form-urlencoded" } } |
Our first log message (“Process 0 is starting”) has a process id of 1044334, a process name of Process-1, and a thread name of MainThread. Meanwhile, our thread-related messages have a different process id, and their process name is MainProcess, and their thread name is Thread-1.
We’ve successfully consolidated all logs—from every thread and every process in our Python application—to Loggly!
Best practices for effective logging in Python
Logging is essential to creating maintainable, debug-able, and operationally transparent applications. Effective logging practices in Python ensure you can monitor, troubleshoot, and optimize your applications with ease. Key best practices for creating efficient and meaningful logs include:Use different log levels: Using various log levels (such as DEBUG, INFO, WARNING, and ERROR) will help you categorize log messages according to their importance and purpose, making for easier searching and filtering.
- Provide context: Include relevant information—such as user ID or transaction ID—in your log messages. Contextual data will help you trace the flow of a particular request or event.
- Avoid logging any sensitive information: To comply with data privacy and security regulations, ensure that you do not log any sensitive or personally identifiable information (PII).
- Log exceptions with details: When logging exceptions, include stack traces and other relevant details to facilitate debugging.
- Use consistent formatting: When you apply a consistent log format across your application, your task of analyzing and searching logs will be much easier.
- Leverage log aggregation: As we’ve already covered, using a centralized log management platform to aggregate logs from various sources will provide you with unified monitoring and analysis.
When your logs are useful and actionable, they become a vital resource for understanding application behavior, identifying issues, and informing business decisions. By following best practices and leveraging log aggregation, you can set up alerts, perform comprehensive analysis, and turn your logs into valuable insights.
Conclusion
In this post, we’ve looked at the added complexity of logging in threaded or multiprocessing Python environments. Instead of employing cumbersome workarounds for logging to a single file—as is especially needed when working with multiple processes—we’ve seen how simple it is to use the HTTPHandler for sending all logs to a centralized platform such as Loggly.
By sending logs across all your Python applications, processes, and threads to Loggly, you have a single location from which to collect, analyze, and correlate all log data. With fast log filtering and searching, coupled with continuous monitoring and alerts, you can easily set up notifications when your Python applications encounter exceptions or exhibit anomalous behavior.
To get started with Loggly today, create a free account to try it for 30 days. You can also speak with our team of experts to learn more about how Loggly can meet your unique business needs.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Loggly Team


