Elasticsearch Filters Put Time on the Side of Log Management Users
Filters Are an Effective Way to Cut Elasticsearch Processing Times
Elasticsearch filters are a simple way to increase the performance of your Elasticsearch cluster. Any time that you’re dealing with large indices, reducing the amount of index you must use to find your results will result in faster search times. Filters give you a way to identify up front which documents you really care about, giving Elasticsearch less work to do when it processes your queries. They can eliminate a large part of your index in one fell swoop.
What we’re going to focus on here is how filters work with time-based data and how to approach the more general problem of evaluating the benefits that filters can provide.
Time Plays a Big Role in Log Management Searches
When you’re trying to solve a problem using log data, time is almost always part of your searching equation. Either you’re looking at the most recent logs, or you’re looking at a specific time period when you know something happened. Therefore, filters presented an obvious solution to improving search performance for our users.
Elasticsearch Filters Give Loggly a Two-for-One Advantage
Loggly gains a double benefit from filters:
- Because data streams into our service chronologically, time filters provide a theoretical “slice” that can reduce the search space dramatically.
- Because Lucene creates segments over time (in other words, new segments are time-based), filters can remove entire segments of an index. While this is not strictly true, thanks to the complexities of the merge process, it is a reasonable approximation to reality.
How We Set Up Our Time Filters for Maximum Reuse
If you design your filters so that they’re reusable, you can amortize the cost of creating them over more search queries. This tenet is at the center of the approach we took.
We could have created time filters for each query our users performed covering the exact time range of the query, but these filters would only be reusable for a small number of queries, as our users refined their queries within that time range. Instead of creating a filter that says, “For this specific time range (accurate to the millisecond), these are the events we care about,” we focused on creating filters that can be reused many times. We traded 100% accuracy in the filter for reusability. Our filters include events that fall outside the time range of a specific query. Because of this, we have some additional cost to eliminate those in each query, but we still get a net benefit because we also filter out many other documents within the index.
A fundamental part of our filters is that they are aligned on and multiples of what we call “natural” time boundaries and lengths. By “natural,” we mean instantly understandable to a human. All of our filters start at the top of the hour; this is what we mean by alignment. All of our filters are also multiples of one hour.
This approach fit well with many of our customer use cases:
- A user looks at an hour’s worth of data and then realizes he needs to see three hours. The one-hour query filters can be reused to speed up the three-hour query.
- A user periodically refreshes the page to see the freshest data in Loggly Dynamic Field Explorer. Constructed correctly, filters make these reloads much faster.
Once we had decided that all filters start and end on hour boundaries, we still had to decide how long to make them. Theoretically, we could cover a day with:
- 24 one-hour filters
- 12 two-hour filters
- 8 three-hour filters
- and so on
Through testing based on our customer use cases, we decided to use two-hour filters every two hours. For example, if we know that we have a filter for 12:00 – 2:00 PM UTC and one for 2:00 – 4:00 PM, we can directly use the filter for any given query by specifying it as a time range filter. If it doesn’t exist, it is created on the fly.
Time Filters Do Make a Difference
Our testing was done using indices containing real user data, and we also used real user queries. We set up a separate testing pipeline to siphon off the data we needed from our live production stream and started indexing and searching that data. This testing method gave us a good approximation of what we could expect in production since it replicates the near real-time nature of our indices.
Once we deployed to production the code that used these filters, we verified that they were behaving as expected. Of course, the live production environment has more data, more varied data, and more and more varied queries than our test bed, so the results of testing on a sample set can never be 100% accurate. We actually saw slightly better performance in production than these tests predicted, which was an unexpected bonus.
Since our production environment is evolving quickly, there is no easy way to show you a direct before-and-after comparison (other changes we made at the same time also improved performance), so instead we’ll show you the test results, which more clearly demonstrate the impact.
This graph shows the percentage improvement we saw in query performance for filtered queries vs non-filtered (using our two-hour filters):
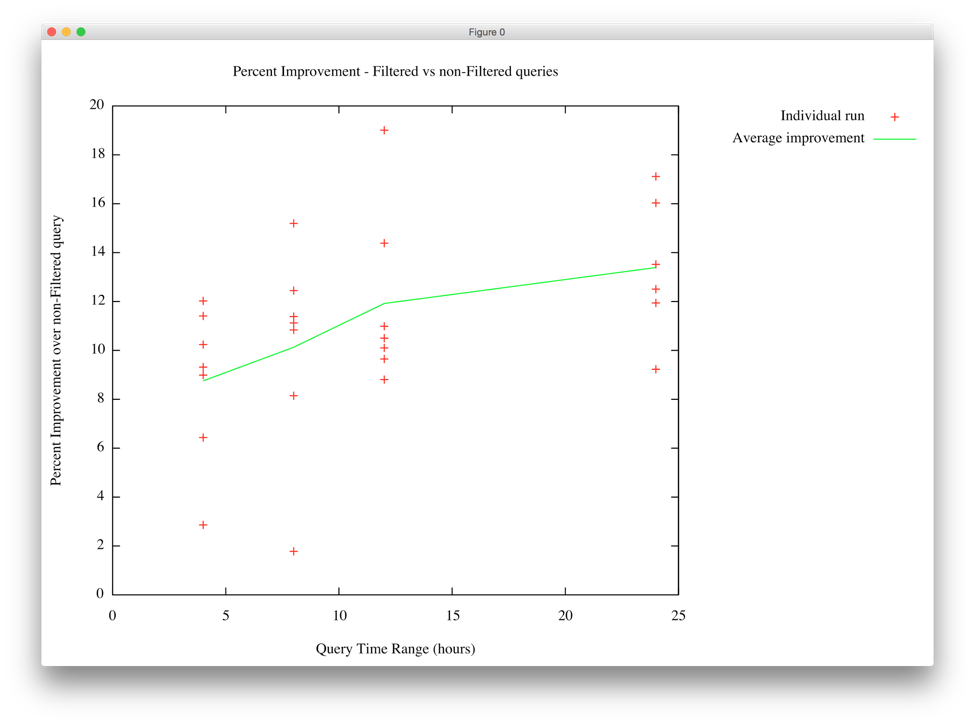
As you can see, using filters improved our performance by between 8.8% and 13.4%, and the impact increased as the time range of the query increased. This is to be expected because longer time-range queries are going to be using filters created for more stable data. By that we mean that as data ages, the Lucene segments in which it is contained tend not to change much. Data closer to the current time is being written to smaller segments that are being actively merged, so a filter on that data will need to be rebuilt periodically to account for those merges.
The other key thing to note is that there is a fairly wide range of values within the individual test runs. This is to be expected since the data is constantly changing.
However, we never saw a test where the filtered queries ran slower than the unfiltered queries. Therefore, there is no question that filters are a net win. Search performance tuning can be a frustrating experience at times because you often have to deal with cases where there is an improvement in one area but a degradation in another. The decision to deploy a change like that can be quite complex (and often protracted). Our filters implementation didn’t put us in this predicament. It’s really satisfying to have a clearly demonstrable, 100% positive change.
Debunking Common Fears About Filters
When we started working on our filters, we read about concerns that they could fill up our heap. Fortunately, we haven’t seen that.
A big reason for this is how we build our indices. Data is constantly streaming into our indices as Loggly collects it from customers. Periodically, we roll our indices, so they’re always “aging.” Once they reach a certain age, we move them from our “hot” nodes (where indexing happens) to our “cold” nodes, where they are search only.
Because our query stream biases toward recent data, we actually didn’t see the value of creating filters for cold data. One of the primary reasons for this is that once data is “cold,” it is usually at least a few days old and searches for it tend to have very wide time ranges (comparatively speaking). Because of this, and because our indices tend to be less than a day long, many of the queries that hit these indices span the entire index range. Creating filters for these queries would essentially be creating filters that match every document in the index.
A second reason is that we chose our filter lengths so that there were relatively few filters needed on any given index. If we had chosen a shorter time range, we would have created more filters, putting more pressure on our heap. We did test other filter lengths, but found the two-hour filters to be the best overall. Similar to Little Red Riding Hood’s preference, they’re not too big and not too small.
The Bottom Line on Time-Based Filtering
In general, Elasticsearch filters can offer significant performance benefits. We see an average of 10-15% improvement in production (and up to double that in some cases) using a very simple time-based strategy. This improvement is felt every time one of our customers executes a search, and we know that our more established customers have noticed the change. We love hearing that the product seems snappier.
We think we’ve found a good balance between performance, heap usage, maintenance, and understandability. This can be tricky because although we know that we can improve it further by adopting a more nuanced approach, the incremental benefit needs to be unambiguously positive to offset the increase in complexity. You should never underestimate the value of being able to explain something in a sentence or two, with no provisos to complicate that explanation. A simple approach also means simpler, more reliable code and simpler operations.
We run multiple clusters, and each of those clusters has slightly different performance characteristics because they serve different sets of customers with different data and different query streams. We could optimize our filters for each cluster based on these differences but choose not to: Every cluster uses the same filter parameters for now. We are constantly monitoring these clusters, however, and we can move to per-cluster filter parameters if we see the need.
If you’re starting to look at filters, our advice is:
- Design for maximum reuse. If a filter is not going to be used often, it may not provide much benefit. In our case, time was the natural thing to filter on. In yours, some other factor may be important (geography, tenant, etc.).
- Test, test, and test some more. Make sure you can get a reasonable estimate of the impact filters will have by getting as close as you can to production in your test bed.
- Keep it simple to start with. Deploy the simple approach and verify that your tests are telling you the truth. Then you’ll know exactly how your filters are helping.
- Monitor and tweak. Production is the only test that really matters, and it’s also the place where insight into your improvements are most likely to happen.
Most importantly of all, experiment! We tried many different approaches before settling on the filters we’ve described here. You should too.
Find more Tips to how to Optimize and Speed Up Elasticsearch
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jon Gifford