Why Loggly Loves Apache Kafka, and How We Use Its Unbreakable Messaging for Better Log Management
This post originally appeared in the developer tech blog on June 10, 2014.
If you’re in the business of cloud-based log management, every aspect of your service needs to be designed for reliability and scale. Here’s what Loggly faces, daily:
- A massive stream of incoming events with bursts reaching 100,000+ events per second and lasting several hours
- The need for a “no log left behind” policy: Every log has the potential to be the critical one, and our customers can’t afford for us to drop a single one
- Operational troubleshooting use cases that demand near real-time indexing and time series index management
At Loggly, our growth has been both amazing and challenging. We aim to be world’s most popular cloud-based log management service, but we also want to be a great neighbor. As such, we’re committed to open source technology and to giving back to the community. Besides just sharing code, we wanted to share our knowledge.
In this post, I’ll talk about our experience with Apache Kafka: how it shaped our development approach and why Kafka is such a great fit for cloud-based applications like ours.
Need Queuing? Enter Apache Kafka
With a couple of years of log management experience under our belts and a full appreciation of the unique processing challenges that we faced, we began our Gen2 development by creating high-performance log collectors written in C++ and capable of ingesting massive amounts of data. We also saw that these collectors could easily outpace our downstream processes and knew we would need to continue to collect no matter what. We had two options for creating an internal buffer:
- Buffer locally in the collector process
- Create a queue that’s external to the collector process but highly performant and reliable
That’s where Kafka came in.
How Kafka Helped Us KISS
The first pass at our Gen2 service included Kafka along with Cassandra, Storm, and ElasticSearch. However, both before and after Gen2 launch, we had major optimization efforts underway. We were always looking at every opportunity to streamline our solution, reduce overhead, and increase its performance – while applying Loggly’s “no log left behind” and absolute resilience principles.
We knew that the core of our system was scalable, so we simplified it to the point where we could take full advantage of the scalability of each piece.
- We removed Cassandra before launch. We realized that as our design evolved, we were only using it as a queue – a task which Kafka could do better.
- We removed Storm after our September 2013 launch, and that’s a longer story. You can read about it here. In a nutshell, Storm is super powerful and really cool, but its power didn’t lend itself well to our use case.
Keep it Simple, Stupid: maybe a silly motto, when you’re designing a scalable cloud-based service, one that makes a lot of sense. Our current testing has demonstrated that we can successfully process sustained rates of 100,000+ events per second, per cluster, each with an average of 300 bytes per message.
Kafka Offers an Attractive Value Proposition for Big Data Developers
Kafka makes it really easy to design a system for resilience and scale – which are really critical attributes for most cloud-based applications.
- No single point of failure: Every day, we move terabytes of data through our Kafka cluster without losing a single event. We use age-based retention to purge old data on disks.
- Low latency: 99.99999% of the time our data is coming from disk cache and RAM; only very rarely do we hit the disk.
- Performance: It’s crazy good! We currently have a bunch of Kafka brokers running on m2.xlarge instances backed by provisioned IOPS. One of our consumer groups (eight threads) which maps a log to a customer can process about 200,000 events per second draining from 192 partitions spread across three brokers.
- Scalability: Its ability to increase the partition count per topic and downstream consumer threads provides flexibility to increase throughput when desired.
What Turned Our Kafka Crush into True Love
Distributed Log Collection
A net-centric business model means that Loggly has customers located throughout the world, so we have local pods and collectors spread all over the Internet with local Kafka deployments. Even when we lose connectivity, we can collect our customers’ logs. As soon as the network comes back, Kafka sends the logs downstream to the rest of the pipeline.
More Efficient, Effective DevOps
When we saw the value that Kafka provided to our log collector, we began to use it in more places. Deploying Kafka throughout our pipeline makes it easy for us to disable certain parts of the system (for troubleshooting or upgrades) without worrying that we will lose customer data. For example, when we are ready to add support for a new log type into our automatic parsing capabilities, we simply turn off the existing parser, deploy the new one, and process the logs that Kafka has queued up.
Controlling Resource Utilization
Our collectors need to be as simple as possible for resilience and reliability reasons, so they have minimal business logic or intelligence. When we recognized the need to add intelligence into our pipelines so that we could better manage quality of service for our customers, we naturally turned to Kafka.
Our pipeline now looks like this:
- Our log collectors write to a single, undifferentiated queue and are written to be fast and robust.
- A mapper performs validation and cleanup on the raw log data and writes to a second undifferentiated queue.
- Next, we apply business logic and policies using Kafka topics. These include quality of service rules that split our data into different queues based on usage patterns we see with our service. For example, we identify “noisy neighbors”—customers who are generating log volumes that are many times the normal amount, either inadvertently or because their application is experiencing big issues—and route them to a separate queue.
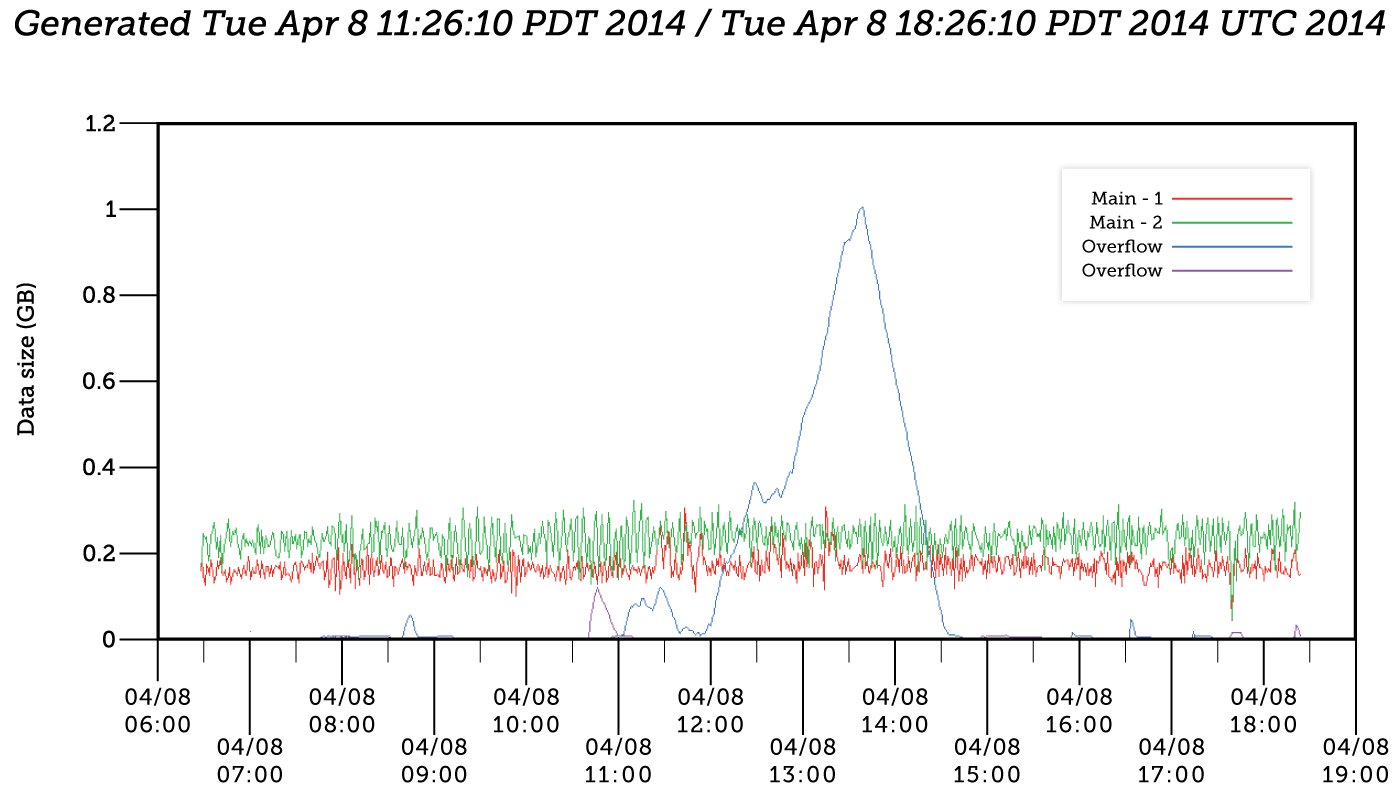
Multiple, differentiated queues allow us to process different data at different rates while processing everyone’s data more efficiently. And the likelihood of any one customer affecting others has gone down significantly. This is evident in the figure above: We received a burst of data from one of our customers, but we shunted the bursting customer to an overflow topic. We then processed this data in a throttled manner. As we can see, the other main queues were not affected at all
Because Kafka topics are very cheap from a performance and overhead standpoint, it’s possible for us to create as many queues as we want, scaled to the performance we want and optimizing resource utilization across the system. Because they can be created dynamically, we can make our business rules very flexible. We don’t have to worry about Kafka constraining us in how many queues or partitions we use.
Kafka in Summary
Because its design is so elegant, Kafka has helped us improve the performance of our service for all customers. We are confident that we can scale it to the volumes and rates that we expect in the future, and we know that it will be fairly simple to address new customer needs and use cases. We don’t have to think about Kafka anymore; and we’re free to focus on other things that will differentiate the Loggly service. (Sign up for a free trial so you can see those things for yourself!)
PS: If you love Kafka as much as we do, and would like to contribute and work with Kafka and other big data technologies, consider joining us. We are hiring in the infrastructure team.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Hoover J. Beaver


