Node.js Error Handling Explained
Introduction
Errors—every programming language has them under one name or another, and the Node.js environment is no different. Node.js includes only a handful of predefined errors (like RangeError, SyntaxError, and others), all of which inherit from Error. The official documentation is a recommended read. Note that the documentation refers to exceptions as well, but don’t be confused: exceptions are targets of a throw statement, so essentially they are errors.
The next important thing to understand is the nature or category of the error. Put simply, it can be either an operational error or a programmer error. Programmer errors are bugs and should be dealt with in your code. This is the category we will concentrate on in this article. Operational errors are not bugs. For example, your system may run out of memory. It’s a good practice to log and monitor for them so there is enough data to analyze and find a root cause.
If you are using Node.js for some sort of distributed systems (which most likely you are, but maybe not given the popularity of Electron or ReactNative for development using Node.js), it is important to log your errors with as much context data as possible on a centralized logger. This data can give valuable and actionable insights and help you solve some edge cases. For instance, some monitoring systems will start firing alerts or incidents if the level of logged errors jump to more than five percent of incoming traffic.
We will be primarily focusing on multi-node Node.js systems so we can ease up a little and disregard error peculiarities of fronted nature (found in browsers).
Node.js Errors: A Brief Introduction
Usually we just handle this by throwing an error with some meaningful description with a stack to help us identify the cause of the problem down to the line of code. But what if the existing error types are not enough? We can simply create our own and so add more relevant data to the error.
There are a few things worth noting before we get into creating our own errors. First of all, do not throw strings! You can throw strings in JavaScript, but if you do it in Node.js, you’ll lose all the stack information and the rest of the properties that are contained in the error object.
Secondly, your errors might be too specific and may not be supported in other frameworks (i.e. they don’t care about your “UhOhProblemoError”). If you still want to maintain your own error types, you can organize them in separate modules, reuse them in your applications, and even publish on npm.
Custom Errors in ES5
To create a custom error class using Node.js, you can use this example:
It’s pretty straightforward, and you can even play around a bit to avoid using a new keyword so much by creating an instantiation function that will do new invocation.
Warning: In ES6 it is quite normal to extend an Error, but in ES5 you cannot extend native objects like Array or Error which can cause problems if you are transpiling from ES6 to ES5.
Custom Errors in ES6
Here is a custom error in ES6:
It’s fairly straightforward to create. If you take look at it (and other code you might have that includes the class statement), you might recognize how your code is becoming more and more like Java/C# code. You may or may not like that, depending on which “camp” you are from. ES6 classes are syntactic sugar for prototypal inheritance, and some people from the JavaScript community hold strong opinions that put them in pro (it’s easy to use and attracts developers from other languages) or con (alienates developers from prototypal inheritance) “camps.” My advice is this: If you and your team like it, your code reads better, and you can back it up by reasonable conclusions, go for it! JavaScript lets you express yourself in many ways and this is one of them. And now you can use the instanceof operator and your custom error class.
Handling Errors in EventEmitter(s)
If you are using any evented code or code that deals with streams, there should always be an error handler ready to do something. Perhaps there is not enough information to take action and remedy the problem, but at least you will be aware of it. EventEmitters fire an error event (and so should you in case you are writing one yourself) and you can listen to it like this:
If the event fires and there is no error listener like the one described above, it propagates to the Node.js process and will print the stack trace and crash it! To avoid this you can listen to an uncaughtException event on the process object like this:
Handling Node.js Errors when Using Promises
Promises are ubiquitous in Node.js code and sometimes chained to a very long list of functions that return promises and so on. Not using a proper .catch(…) rejection handler will cause an unhandledRejection event to be emitted, and if not properly caught and inspected, you may rob yourself of your only chance to detect and possibly fix the problem. Here is how you can set up a listener:
Or if you are using Bluebird instead of native promises, here is a guide that shows you how to set it up.
It is a good practice to set up a listener for an unhandledRejection event and log or even count the number of occurrences just to know what happened in your system and inspect possible instabilities due to improper rejection handling.
Errors and Generators
Generators are essentially iterators (in JavaScript that allow you to resume the execution inside a function using the yield keyword. You get back an object with next() function that holds a value and a done variable (so you know you cannot iterate over it again). So this, in the end, allows us to compose our asynchronous code to look synchronous. Is there anything special about error handling? Well, not really. The try-catch block and throw statement work like a charm.
Consider this:
The same classic error handling principles apply if you throw an exception inside the generator. You can catch the error inside the try-catch block.
Useful Node.js Modules for Dealing with Errors
Since the node package manager and Node.js ecosystem are package rich and developers like to share, you can find various utility modules to help you deal with errors.
For custom ES6 errors, you can use the es6-error package and cut down boilerplate code. If you are dealing with http errors, reuse the http-errors module so you don’t have to reinvent the wheel (unless you really need to).
Most interesting and widely popular is the VError module that gives more “life” to your errors. It contains VError and WError classes. VError is almost like a classic error but it allows you to layer multiple errors and have a better and more meaningful output:
WError is a wrapper for layered errors (VErrors) that skims on some details of the error message, which is great for showing it to non-tech-savvy personnel, but all the info is preserved and can be successfully logged for investigation.
Logging Node.js Errors
The simplest thing you can do with your errors is to log them. You can then analyze their frequency or depending on your logging platform, act on them in real time. In multi-node systems (e.g., microservices), it is even more important to aggregate error information in a centralized manner. Who wants to inspect huge log files on each node? It’s time-consuming, error prone, and terribly boring. Pick some of the known logging platforms (or create your own) and start using them. Chances are they are already supported by your favorite loggers like Winston, Bunyan, and Morgan.
Aside from logging errors, log contextual data as much as possible as it may be the key to helping you find solutions to problems in distributed systems.
Consider these examples:
- In the case of a 404 error, you would like to know the route, so it needs to be logged.
- If your system is consuming other services and is itself a producer service, it is very useful to have some correlation ID that will allow you to singularly pinpoint the path through your code that leads to an error, even if the path traverses through other systems.
For example, on a REST API, correlation ID could be a unique Request-ID. This blog post gives an example of how you can trace a sequence of events with Loggly.
There are lots of logging platforms out there. It’s up to you to find the the one that works best for you and your team.
We are going to focus on Loggly because it is simple to use, well supported for Node.js development, and has some of the basic traits we need, such as visual displays, time range searches, and alert monitoring, among others. It also handles large flows of log data very well.
Take it for a spin using a free trial.
For example, take loggly-express, an expressjs-powered Node.js web application with setup Loggly request/response and error logging using Winston and dot-env.
If you run the app, you can see the information and error being logged and uploaded to Loggly.
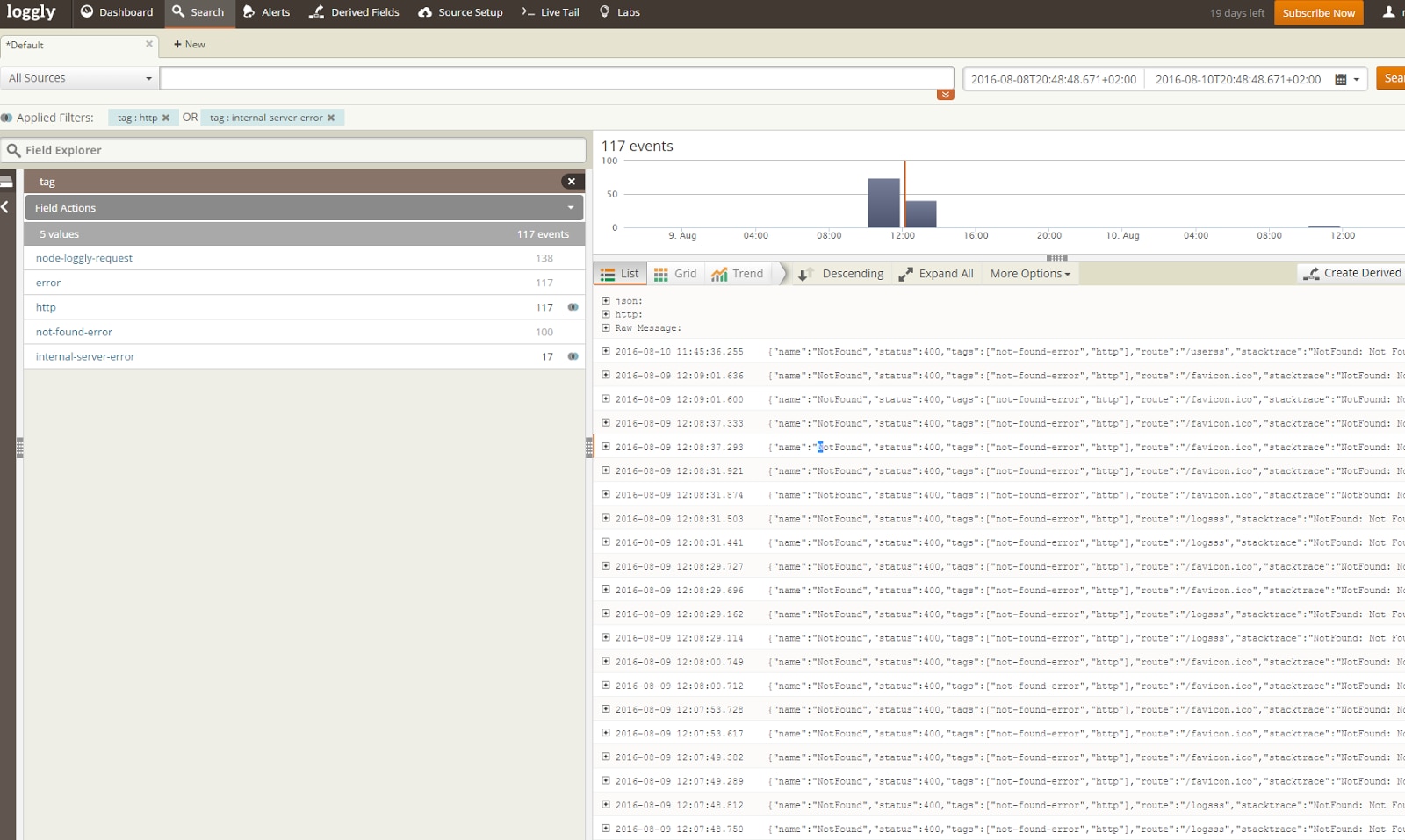
As illustrated above, Loggly also supports tags, so giving the tags to the logger method will allow you to more easily search common type of errors in the Loggly interface.
Here’s an example logger using tags:
Another great feature of the Loggly logging platform is alerts. Alerts allow you to do more then just send an email. You can configure them as a webhook to fire an event back to your application and allow you to react.
The image below shows how we can configure an alert to use a webhook to alert us if we have too many internal server errors in in a given timeframe.
A small expressjs router reacting to a webhook can be implemented as in this module. It is quite useful if you have a use case where you need some real feedback from your app and you have an idea on mitigating a problem you might get notified of.
Lastly, it is always a good thing to know your logging platform and its features. Things like live console (log tailing) and log data visualisations are starting points for good engineers to diagnose complex problems.
Conclusion
My parting advice: Know your logging platform. Know it well. Know its features, quirks, and problematic areas. Use it wisely and within budget.
Log data does not mean anything if you do not act upon it or at least examine it. It is a good practice to construct a detailed guide for performing log analysis (at least production) and presenting results to your team. Make a habit of doing that in some repeated time interval that suits you (weekly, bi-weekly, monthly) and rotate the team members performing it so that everybody gets a chance to be exposed to data and possibly offer a fresh opinion on how to update error logging or even find solutions for errors that have been hard to reproduce outside the production environment.
And most importantly, have fun handling errors in Node.js! Let me know in the comments how things are going.
More Reading
If you are interested in expanding your knowledge on the topics of errors and logging in general I suggest these articles:
- Error Handling in Node.js by Joyent,
- Angular exception handling made simple with logging
- Logging and Log Management by Chuvakin, Schmidt, and Phillips
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Mihovil Rister

