Structured logging then and now
Logging is the main way for service programs, that is, programs that do not have an interactive user interface, to inform users and admins of what is happening and where problems might be. In the early days of computing, there usually was just a single system and only a handful of services. Log messages were easy to sift through manually, and the only structure they needed was a timestamp associated with some free-form text field.
Jun 04 09:46:34 loki.jorgenschaefer.de sshd[3548]: Disconnecting: Too many authentication failures for invalid user root from 11.24.17.19 port 47358 ssh2 [preauth]
More log output, more problems
Problems arose when more and more services with more and more log output appeared. More structure was needed to make it easier to use programmatic help to sift through the piles of log messages. For example, log messages were annotated with priorities to make it easier to filter out non-critical information until a deeper analysis was necessary.
But over time, it became clear that priority is not the only relevant information in a log message. An admin might need to check all log messages for a specific resource, or all log messages with a particular status code.
Categorizing log messages requires context
But it gets worse. Sometimes, the relevance of a message depends on the context:
- A single web server log entry about a page not being found is not a problem. A sudden spike in such messages can indicate a serious problem.
- Some messages even contain metrics, like the time spent on some operation, where importance can only be derived by looking at a longer history. And here, “important” depends on the question being addressed by the analysis. It can mean a problem that requires immediate action, like when requests suddenly take multiple seconds, or maybe just an indication that a problem will likely happen in the future, like when request times slowly rise over time.

A log message today is not only a simple plain text message describing some event meant for a human to read, but a collection of attributes with values that are processed by a computer, analyzed individually, and compared over time between messages: Structure.
Machines are now the most important log consumers
On the modern web, there are so many services, containers, programs, and processes, all constantly emitting log messages, that it’s basically impossible to sift through them by hand. They need to be processed by machines first and foremost. Human consumption is a distant secondary goal, where the output for a human often involves a processed form of the raw messages.
While it is possible to create tools for computers to analyze free-form log messages and extract data points from those, that is a difficult and error-prone process. It’s much easier for programs to format their log messages right away so that computers can parse them easily.
Cloud native programs that are never meant to be run outside of such large-scale environments, written specifically for them, can use specialized protocols to emit fully structured log messages, like Graylog’s GELF format, or send them to structure-aware log collectors like Loggly’s REST API.
As most environments do not use applications tailored to them exclusively, traditional logging solutions, such as syslog, are often used to facilitate collecting messages from all involved services. These protocols have some shortcomings, like being limited to single-line plain text messages. Structured log messages need to be serialized by log-emitting programs and then parsed by log aggregators.
JSON has become a standard tool for these situations, being widely supported by both programming language libraries as well as log aggregators. This works quite well, and many log aggregators natively support log messages written in JSON.
{"name":"httpd","hostname":"www.test","pid":40161,"level":30,"msg":"retrieved","time":"2017-06-04T12:50:23.851Z","path":"/index.html"}
Loggly will happily consume this message and parse the JSON:
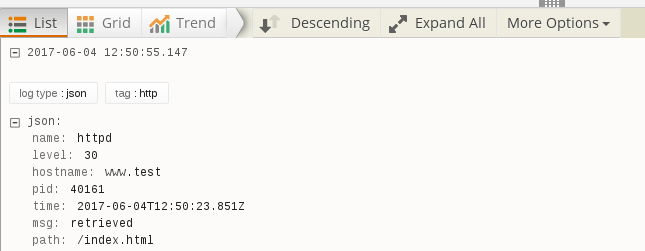
But JSON has a drawback: It’s really annoying to read by humans. As many programs, even when written for cloud environments, are not exclusively used in such large-scale environments, log aggregators are not the only target. During development, programmers still read the log messages manually. In smaller-scale deployments, it’s quite regularly still some admin who is manually sifting through log messages. Even in larger-scale situations, catastrophic failures can mean that an admin needs to dig through raw log messages to find the cause of the problem. Purely JSON-formatted messages make all these use cases more difficult.
Semi-structured logs support both machines and humans
Because of this, many programs now emit something you could call a semi-structured format, trying to be both quickly readable by a human as well as parseable by a computer. These log messages typically start with some plain text message description, followed by key-value pairs separated by equal signs. For example:
HTTP request succeeded; status=200 request_time=23.53139 bytes=20391
This message format is easily understood by a human, as well as easily parsed by a computer. A human can grasp the meaning just as easily as a log aggregator can parse it to create graphs for the request duration over time. And arguably, such a regular and structured format can be more readable for a human as well.
Lack of a standardized, semi-structured format has driven workarounds
Sadly, there is no standardized format for this. Some programs emit the message description separated by a colon, or a space, or as just another key-value pair. The quoting rules for values that contain white space are not universally defined either. All of this makes uniformly parsing such messages difficult at best. Loggly provides Derived Fields to extract such information from free-form log messages, but such rules need to be created manually for each such field, and parsing unstructured text is necessarily ambiguous and error-prone.
So while this ad hoc format is a step in the right direction, there is still a very long way to go.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Jorgen Schäfer Jorgen is a software developer with more than ten years of experience in both application development and system administration. As a part-time freelancer, he writes technical articles, gives public talks, and provides training services.

