EMR Series 1: An introduction to Amazon Elastic MapReduce (EMR) logging

Introduction
Amazon Elastic MapReduce (EMR) is a fully managed Hadoop and Spark platform from Amazon Web Service (AWS). With EMR, AWS customers can quickly spin up multi-node Hadoop clusters to process big data workloads.
This article will give you an introduction to EMR logging including the different log types, where they are stored, and how to access them. Over the course of a three-part blog series, we will learn how to use those logs to troubleshoot EMR problems and how to send EMR log files to SolarWinds® Loggly® for production monitoring.
Amazon EMR vs. Non-managed Hadoop Clusters
Most production Hadoop environments use a number of applications for data processing, and EMR is no exception. A Hadoop cluster can generate many different types of log files. These log files can be either system-generated, like those created by different Hadoop daemons, or application specific, created from MapReduce or Spark jobs.
Hadoop administrators and developers can use these logs to troubleshoot application failures, slow-running clusters, or even failed daemons.
Amazon EMR offers some advantages over traditional, non-managed clusters.
For example, when installing a cluster, Amazon EMR allows users to choose a number of applications like Spark, Hive, Presto, Pig, or Hue to be installed as well. Once the options are chosen, EMR takes care of the rest. For a non-managed environment, once the base cluster is set up, users have to manually install these components.
There are also some major feature differences between EMR and standalone Hadoop installations:
- EMR cluster nodes are classified as master nodes, core nodes, and task nodes. In traditional Hadoop clusters, we have name nodes, secondary name nodes, resource manager nodes, and data nodes. There is no one-to-one mapping between these two classifications. For example, an EMR master node does not necessarily represent a name node.However, the naming difference is not important because for all intents and purposes, EMR offers all the features of a full-blown Hadoop environment.
- A stand-alone Hadoop cluster would typically store its input and output files in HDFS (Hadoop Distributed File System), which will be mapped over the combined storage space of all the data nodes in the cluster.EMR also supports HDFS. Here, the file system is mapped to the combined storage of the EC2 nodes of the cluster. However, it also supports something called EMRFS (Elastic MapReduce File System), which is HDFS’ implementation over S3 file system. Using S3 as the underlying data storage has the advantage of persistence. If the cluster is terminated, data files remain accessible.
- EMR also allows cluster logs to be saved in S3 buckets. Once again, this means the logs are persisted even if the cluster is terminated.
- An EMR cluster can be run in two ways. When the cluster is set up to run like any other Hadoop system, it will remain idle when no job is running. The other mode is for “step execution.” This is where the cluster is created, runs one or more steps of a submitted job, and then terminates. Obviously the second mode of operation saves costs, but it also means data within the cluster is not persisted when the job finishes. This is where EMRFS becomes important.
EMR Log File Types
Like any Hadoop environment, Amazon EMR would generate a number of log files. While some of these log files are common for any Hadoop system, others are specific to EMR. Here is a brief introduction to these different types of log files.
- Bootstrap Action Logs: These logs are specific to Amazon EMR. It’s possible to run bootstrap actions when the cluster is created. An example of bootstrapping can be installing a Hadoop component not included in EMR, or using a certain parameters in a configuration file. The bootstrap action logs contain the output of these actions.
- Instance State Logs: These log files contain infrastructure resource related information, like CPU, memory, or garbage collection.
- Hadoop/YARN Component Logs: These logs are associated with the Hadoop daemons like those related to HDFS, YARN, Oozie, Pig, or Hive.
- Step Logs: This type log is specific to Amazon EMR. As we said, an EMR cluster can run one or more steps of a submitted job. These steps can be defined when the cluster is created, or submitted afterwards. Each step of a job generates four types of log files. Collectively, these logs can help troubleshoot any user-submitted job.
EMR Log File Locations
Master Node
By default, Amazon EMR saves all its log files in the master node, under the /mnt/var/log directory. There will be different subdirectories for different types of log files as we described before. The directory listing below shows the contents of one such location:
[hadoop@ip-10-0-8-117 ~]$ ls -l /mnt/var/log/ total 216 ... lrwxrwxrwx 1 root root 46 Sep 16 03:09 bootstrap-actions -> /emr/instance-controller/log/bootstrap-actions ... ... drwxr-xr-x 3 hadoop hadoop 19 Sep 16 03:16 hadoop drwxrwxr-x 2 hdfs hadoop 129 Sep 16 03:11 hadoop-hdfs drwxrwxr-x 2 httpfs httpfs 231 Sep 16 03:11 hadoop-httpfs drwxrwxr-x 2 kms hadoop 210 Sep 16 03:11 hadoop-kms drwxrwxr-x 3 mapred hadoop 127 Sep 16 03:11 hadoop-mapreduce drwxr-xr-x 2 hadoop hadoop 68 Sep 16 03:16 hadoop-state-pusher drwxrwxr-x 2 yarn hadoop 302 Sep 16 03:11 hadoop-yarn drwxr-xr-x 2 hbase hbase 6 Aug 4 01:06 hbase drwxr-xr-x 3 hive hive 66 Sep 16 03:15 hive drwxrwxr-x 2 hive hive 70 Sep 16 03:15 hive-hcatalog drwxr-xr-x 2 hue hue 237 Sep 16 03:15 hue lrwxrwxrwx 1 root root 19 Sep 16 03:09 instance-state -> /emr/instance-state ... ... drwxr-xr-x 2 oozie oozie 309 Sep 16 03:15 oozie drwxrwxrwt 2 root root 6 Sep 16 03:14 pig ... ... drwxr-xr-x 2 zookeeper zookeeper 6 Sep 16 03:10 zookeeper |
S3 Bucket
EMR can also save log files to Amazon S3. Like the master node log location, the S3 bucket will have a number of folders under it.
The S3 log location can only be specified when the cluster is created. With this configuration, the logs are sent from the master node to S3 every five minutes. This can be useful for transient clusters, which are automatically terminated after a specific workload is finished. Since the master node is gone when the cluster is terminated, there is no way to check log files if a job fails. If log files are saved into S3, it will be possible.
On the flip side, a five minute interval may not be enough to capture all log events from the master node, particularly if the cluster is terminated within these five minutes.
The following images show the contents of an S3 bucket with EMR log files in the AWS console. Note how the folders are named: under the bucket, each folder name will represent an EMR cluster’s cluster ID.
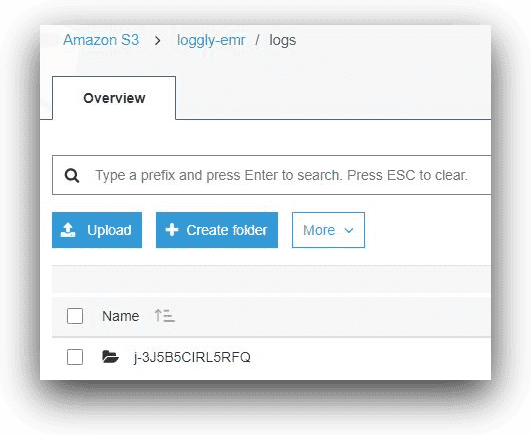
AWS S3, © Amazon.com, Inc.
Inside the folder with the cluster ID, there will be a folder called “node” and a folder called “steps.”
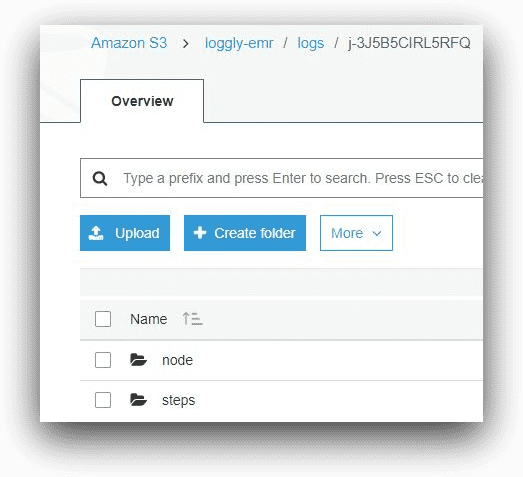
AWS S3, © Amazon.com, Inc.
The node folder will contain subfolders for logs from each of the cluster EC2 instances. Again, the subfolder names will represent the EC2 instance-ids.
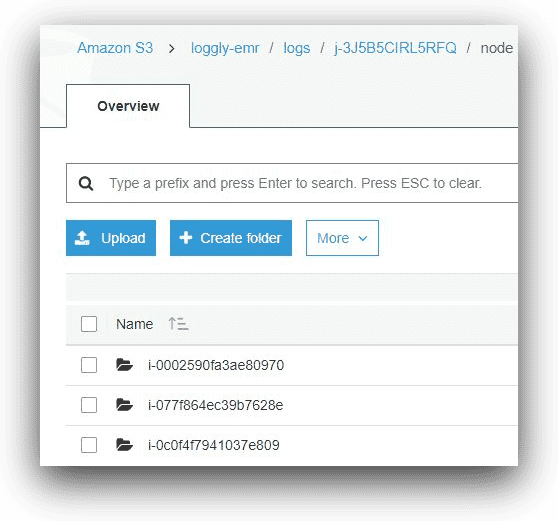
AWS S3, © Amazon.com, Inc.
Under each node’s subfolder, there will be a number of subfolders for log files.
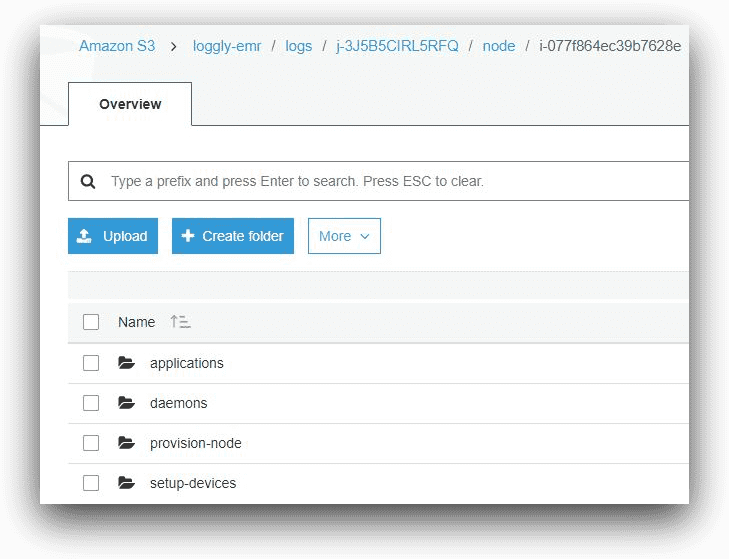
AWS S3, © Amazon.com, Inc.
And under the applications folder of the master node, there will be one subfolder for each Hadoop application installed in the cluster.
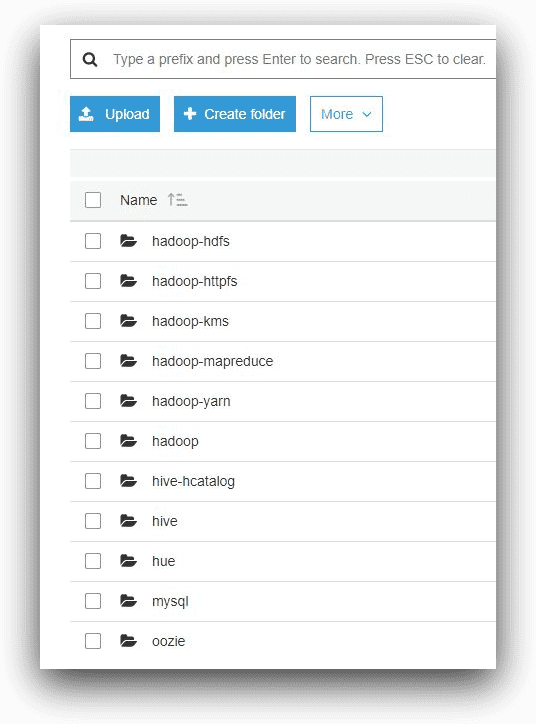
AWS S3, © Amazon.com, Inc.
The following image shows the log files under the hue application’s folder.
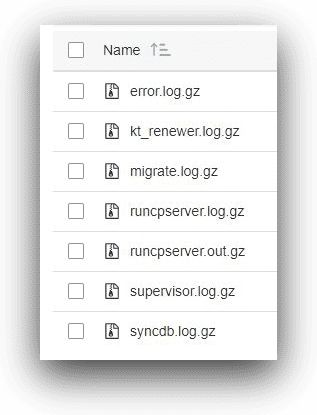
AWS S3, © Amazon.com, Inc.
Going back to the root of the cluster ID folder, the steps subfolder will contain logs for each submitted job’s steps. Each EMR job step will have a step ID, and the subfolder name will reflect that.
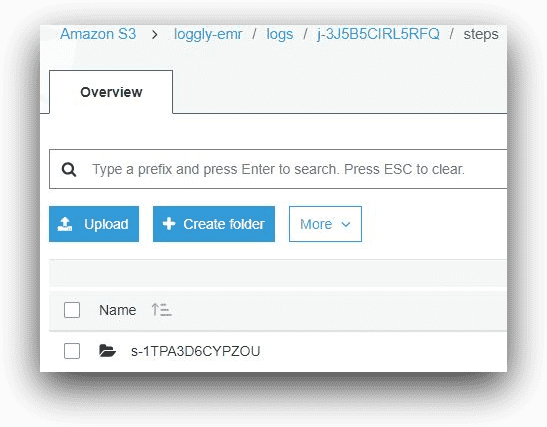
AWS S3, © Amazon.com, Inc.
Each step of a user-submitted job in EMR will generate three types of log files:
- Controller
- Stderr
- Stdoutput
These files will be compressed when saved in the S3 folder.
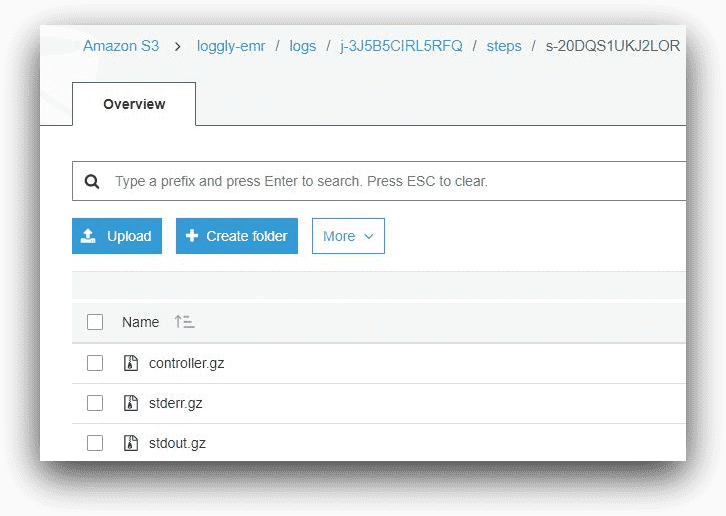
AWS S3, © Amazon.com, Inc.
The controller log shows the actual output of the program as it executes. The stderr and stdout files are for standard error and standard output respectively. If a submitted job fails for some reason, it can be tracked from controller and stderr logs.
Log Aggregation
In a multi-node Hadoop cluster with YARN scheduler, MapReduce programs are run in application containers across data nodes. Each of these containers performs a specific portion of the task on a specific set of data that’s present in that node. The containers are spawned by a node manager service in that node, which in turn is spawned by an application master process. The application master tracks, schedules, and aggregates the results from individual containers across the cluster. The whole process is managed by the Resource Manager daemon running in the Resource Manager node.
Since each container runs its process independently, it also generates its own log file. Looking at the log file, we can see if the container failed for some reason during the processing. However, this also poses its own caveat: The full execution of a MapReduce program is the aggregate of all the associated containers’ executions. If we are to look at a job’s failure as a whole, it only makes sense to have one log file for troubleshooting. An EMR Hadoop cluster can have hundreds of nodes, and each node could be running multiple containers for a job. It’s not feasible to check each container’s log files from each of these nodes. In other words, container log files need to be aggregated for effective troubleshooting.
This is where log aggregation comes into the picture. With a few settings of the yarn-site.xml configuration file, logs from each container are aggregated into one single file. In EMR, this setting can be enabled when the cluster is created, and this is what we will see in the next part of our article series when we create an EMR cluster. With log aggregation, a single file for the MapReduce program is saved in S3.
Conclusion
In this post, we had a quick introduction to Amazon EMR and its different types of log files. We also learned where to find these log files and the need for aggregating these logs.
In the next part of this series, we will create an Amazon EMR cluster and configure it for log aggregation. We will run a data processing job with Apache Hive and try to troubleshoot a failed Hive job from its aggregated logs.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Sadequl Hussain