Integrating Logging into CI/CD
with Loggly, Gitlab, & DigitalOceans's Managed Kubernetes service
In my experience, pipeline monitoring and management is traditionally either left for the last developer who deployed, or unmonitored entirely. This lack of centralized monitoring and production-level resiliency can lead to significant development delays or even bring pipeline and train deliveries to a grinding halt.
But we can do better. With the right tools, we can centrally monitor a pipeline, correlate environment issues from other developers’ changes or running jobs, and prevent potentially catastrophic development freezes and rollbacks, which could save your next sprint.
Let’s look at how you can use SolarWinds® Loggly® in a distributed DigitalOcean’s managed Kubernetes staging environment to implement centralized, powerful monitoring and help your team to quickly and accurately diagnose a managed Kubernetes service.
The Infrastructure
Our infrastructure for this demonstration is simple: A Gitlab helm-based installation into the same Kubernetes cluster as our staging deployment. The runners will log their jobs status to Loggly along with the staging instance of our application. Our cluster is a DigitalOcean-managed Kubernetes cluster with four worker nodes to run our pipelines and stage workloads.
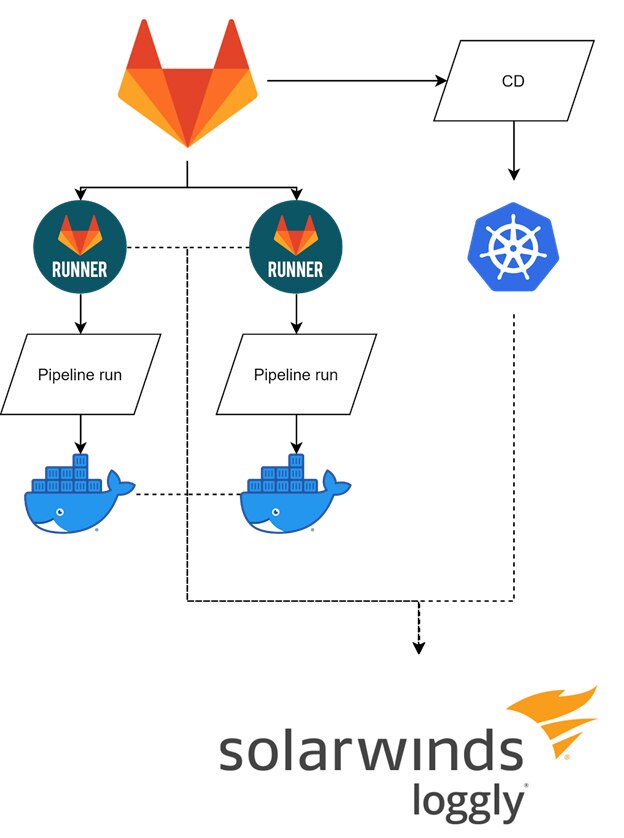
The Logging Setup
While this setup is simple, with such fungible resources in our cluster and such different types of flows running, gathering logs will prove difficult.
- Anything related to host-level resource consumption will have to come from DigitalOcean’s dashboarding with host-level logs from the droplets or from kubectl directly.
- Anything from the pipeline will have to come from the Gitlab pipeline dashboarding or from the ephemeral pipeline-generated containers executing our builds.
Gitlab will persist some level of logging, but those logs will be locked behind user permissions and per-pipeline-per-job windows, which will make correlating errors nearly impossible.
Let’s start by breaking down each core component and its role:
DigitalOcean provides a managed Kubernetes cluster service. This is how we’ll host all of our services. DigitalOcean will deal with the underlying complexities of our load balancers, ingress of traffic, storage needs, and deploy our actual droplets that will be home to our applications.
Gitlab is a suite of self-hosted (they also offer hosted) git repositories, continuous-integration, and continuous-delivery management, and runners that will query our Gitlab instance for jobs they need to execute to test and deploy our code.
Loggly will act as a central platform to which all of our components can send logs. This will then become our single pane of glass to see all the activity in our deployment pipeline.
The Install
The installation of each core component is straightforward.
Quickstarts:
Note: The cheapest DigitalOcean options are insufficient. Be sure to give yourself at least two CPUs and 4GB ram per worker node or Gitlab may consume all your available resources. Additionally, there’s a lot of security built into Gitlab, so I recommend leaning into their certmanager implementation and provisioning a domain to generate your LetsEncrypt certificates.
In my environment, I’ve provisioned six hosts and some dynamic Gitlab runners to run my CI pipeline. I could debug whatever failures I run into using the painful methods described earlier in the article, but with the power of a centralized Loggly monitor at our fingertips, we can already start to see corollary data:
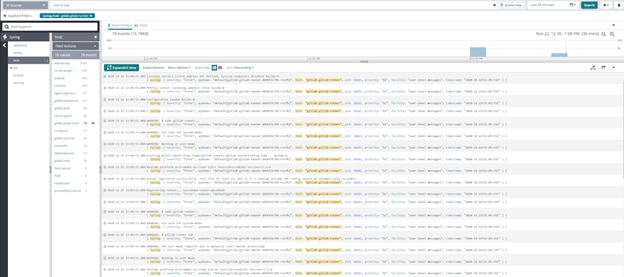
The Results
This is great, but what benefits do we really get by using an extra service?
We gain the power of a single-pane-of-glass (SPOG). Reducing the amount of bookmarks, technical breadth, and time to switch tools will reduce the amount of time it takes to troubleshoot issues and get your devs back to doing what they do best.
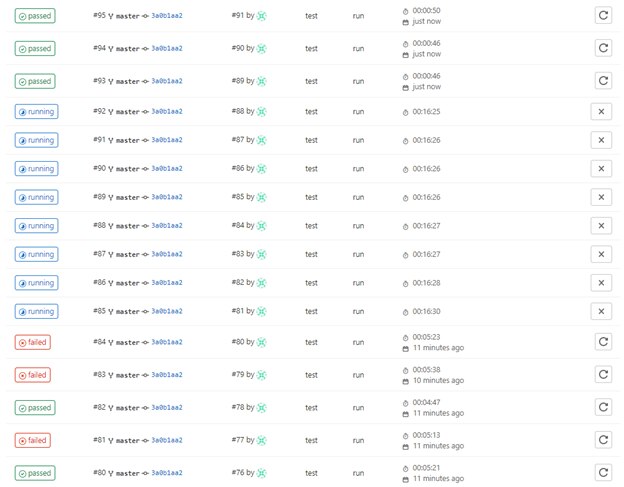
In our example here, we have multiple build tests running for our master on the same build, but some are failing and some are succeeding.
It’s often claimed that Albert Einstein once said, “The definition of insanity is doing the same thing over and over again and expecting different results.” If that’s true, it seems Albert wasn’t a developer…
Issue Identification
Let’s look at each of these jobs one at a time to try and determine the issue. Here’s our example:
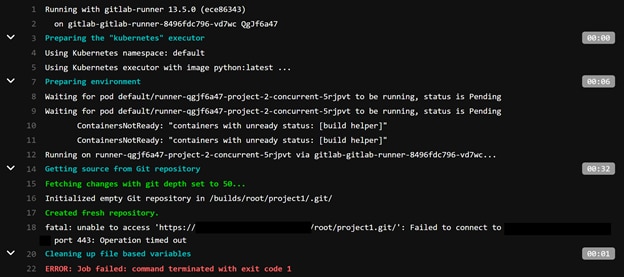
That doesn’t seem related to our code, which is a good sign. And looking at recent builds, they seem to have succeeded consistently. We could end our investigation here and continue about our day—after all, the latest build passed. But who’s to say this won’t happen again if we don’t understand why the problem occurred in the first place?
Fortunately, we have our centralized Loggly explorers we can consult to look at all the levels of our new infrastructure.
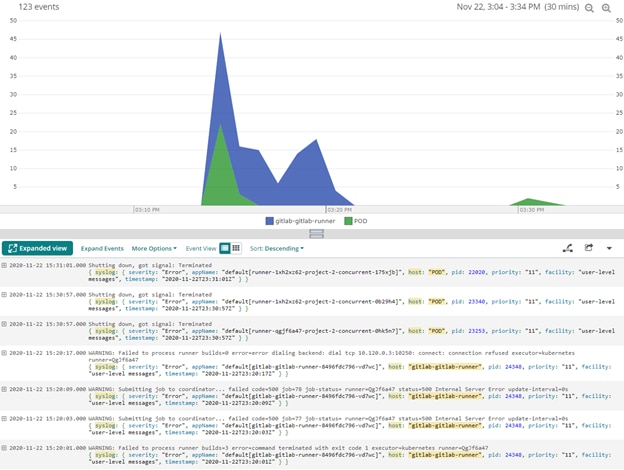
While looking for our runner’s jobs, we can see a clear time when failures occurred. It appears that the failures were consolidated to a small period of time and may have been impacting all pipelines that were submitted to our runners.
Focusing on the Impact Window
What do we see if we look at all our services during this time?
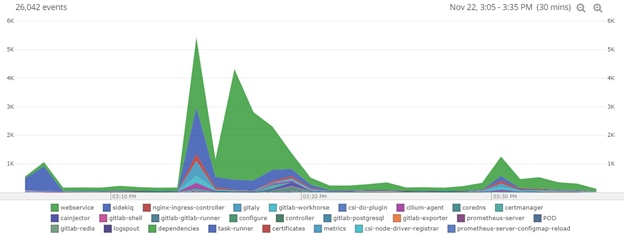
It appears that many of our services were throwing logs in this pattern, and our runner was just a small part of that puzzle.
By digging into the webservice logs in the same explorer, which was what our runner complained about in the initial logs, we see errors connecting to Redis.
"Redis::CannotConnectError","exception.message":"Error connecting to Redis on gitlab-redis-master:6379 (Errno::ECONNREFUSED)"And, finally, Redis shows a shutdown event at the beginning of all this:
1:M 22 Nov 2020 23:14:55.740 # Redis is now ready to exit, bye bye…Following up with our infrastructure team, we can get to the bottom of the issue: Several hosts were restarted during that period for maintenance and the core dependency Redis was a victim.
By using Loggly, we were able to quickly correlate the work stoppage with an actual event in our infrastructure. Additionally, by following the ITIL paradigm of iteratively improving our reliability, we can now work on designing Redis to be more resilient and prevent future outages and build delays. Maybe on the next sprint.
Conclusion
With some thought put into how we digest our logs, and the combination of tools such as Gitlab and Loggly, it’s easy to keep a bird’s-eye view on DigitalOcean performance without sacrificing sanity. It’s important to instill our product lifecycle practices into our entire development lifecycle as it can protect us from one another, and help add resiliency into the core tooling that makes our products great.
The Loggly and SolarWinds trademarks, service marks, and logos are the exclusive property of SolarWinds Worldwide, LLC or its affiliates. All other trademarks are the property of their respective owners.

Loggly Team


